Dev Tools: XYplorer (review 1) - Catalog
currently on version 14.60 I'm a big fan of finding tools that help automate and streamline things that should are routine actions.Surprisingly, I've found it incredibly challenging to move away from the default Windows Explorer for file management, as the familiarity it offers makes it somewhat tough to be patient with learning an alternative, especially if the alternative offers more complication. That's where I stood with XYPlorer for sometime. It is a developer's tool first and foremost. It is complicated, but with this complication comes an extremely robust set of features. I honestly think that I'll never really know all of them, as this is more than just a swiss knife for file management.
This is almost like stepping from a text editor for editing code to a full blown visual studio IDE. There is just that that much to learn! Over time, I'm finding myself less frustrated by using it, and more amazed at the tweaks here and there that can be found that can greatly enhance one's file management and workflow, personal and professional. I won't cover all features, but I think instead of doing a full blown review on the product, I'm going to add some incremental reviews on features as I discover, otherwise the vast feature-set will end up causing nothing but writer's block and I'll never share anything (cause I'll be busy learning)
Catalog
- Replaces Favorites with additional functionality The favorites section is one of my most used features in explorer. I setup the default locations I'm commonly navigating to, such as my SQL Query files location, cloud drives, temporary projects I'm working on, appdata folders I need access to occasionally, and more. XYPlorer Expands on this greatly by the concept of Catalogs. Instead of just having a shortcut, Catalogs allows one to expand the concept of shortcuts far beyond Windows Explorer (hereafter referred to as WE) and combines the favorites functionality with much more features.
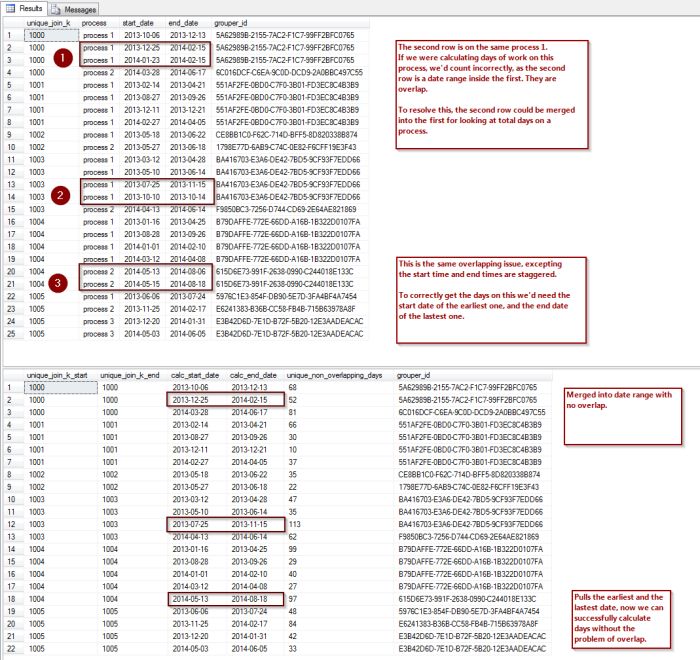
The Tree is an image of your computer's file system. It shows you all what's there. But, most of the time all is just too much... The Catalog is the answer: here you can grow your own personal tree. Your favorite locations are deep down in some heavily nested structures? Lift them to the surface! Side by side with locations from the other end of your hard disk. You can navigate by the Catalog (finally a one-click favorite solution!) and you can drop onto the Catalog's items. XYPlorer Help The catalog houses many categories. Each of these categories can provide various functionality beyond just linking to favorites.
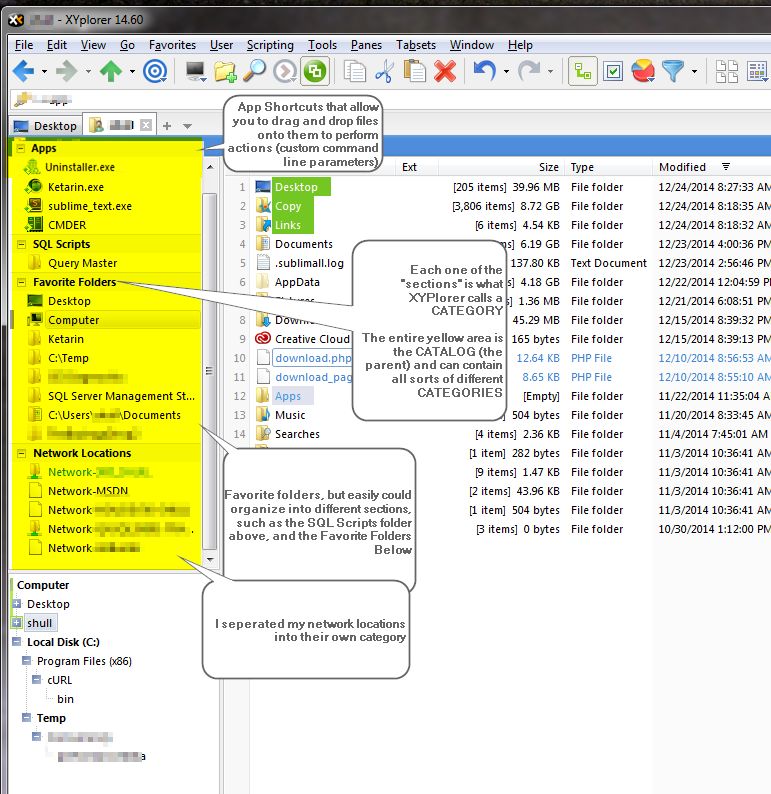
Here you can see applications listed directly. They provide functionality to open the app, open a file you drag onto it with the app (bypassing need to use "open with" dialogue)
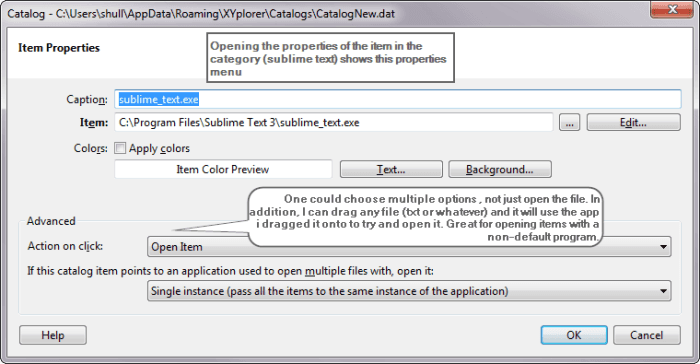
Opening the properties of a file allow one to futher edit the actions the application performs.
 .... to be continued.
.... to be continued.
Lots of functionality in the catalog to benefit from, but time is limited, I'm going to visit further in next post.
note: was given a license by developer to help me evaluate long term. This did not affect my review, as it wasn't solicited at all by XYPlorer developer.