Red Gate SQL Source Control v4 offers schema locks
Looks like the rapid release channel now has a great feature for locking database objects that you are working on. Having worked in a shared environment before, this could have been a major help. It's like the poor man's version of checking an object out in visual studio except on database objects! With multiple developers working in a shared environment, this might help reduce conflicting multiple changes on the same object.
Note that this doesn't look to evaluate dependency chains, so there is always the risk of a dependent object being impacted. I think though that this has some promise, and is a great improvement for shared environment SQL development that uses source control.


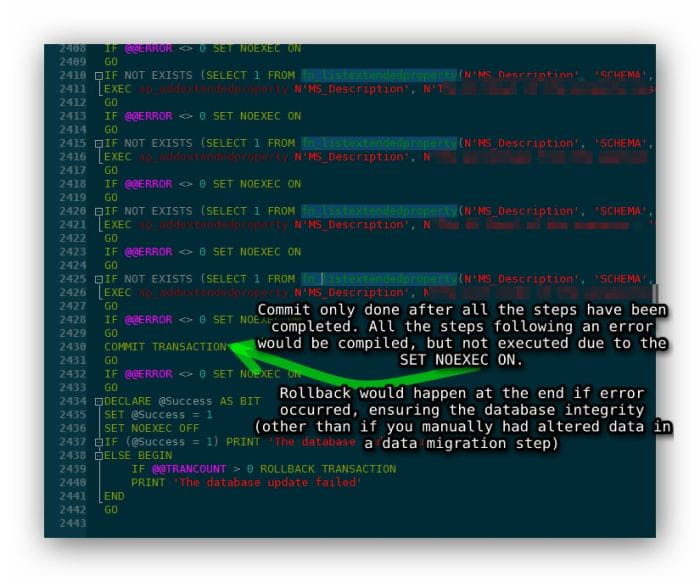
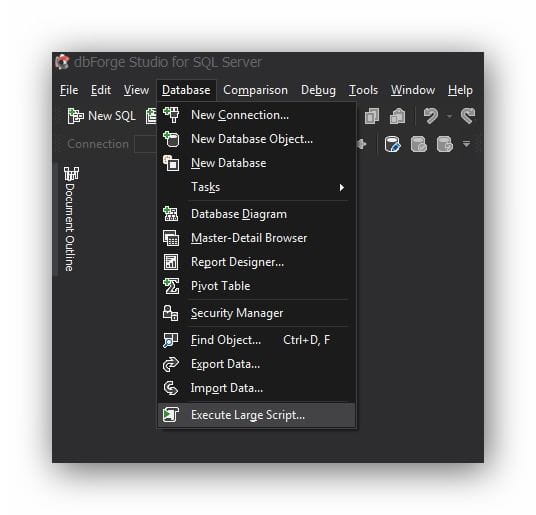
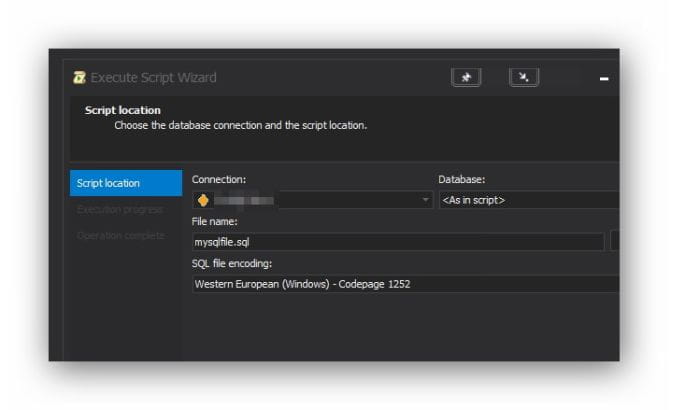 You can see the progress and the update in the output log, but the entire script isn't slowing down your GUI. In fact, you can just putter along and keep coding.
You can see the progress and the update in the output log, but the entire script isn't slowing down your GUI. In fact, you can just putter along and keep coding.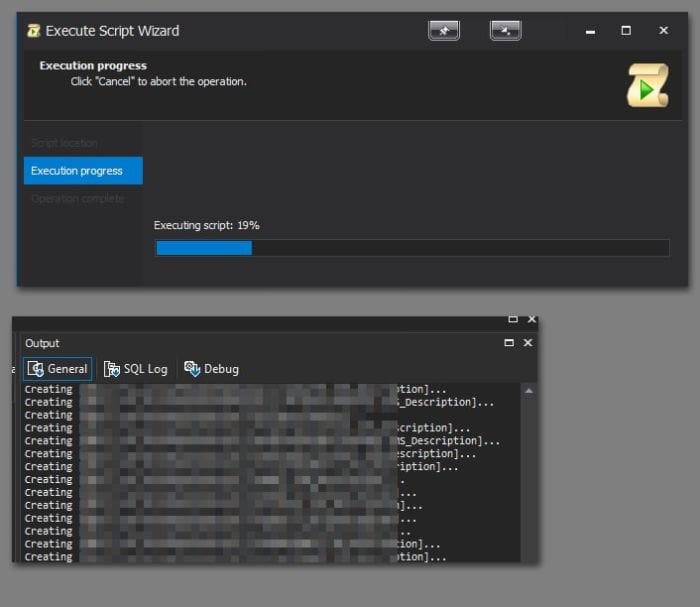 Other options to accomplish the same thing include executing via SQLCMD, powershell, or breaking things up into smaller files. This just happened to be a pretty convenient option!
Other options to accomplish the same thing include executing via SQLCMD, powershell, or breaking things up into smaller files. This just happened to be a pretty convenient option!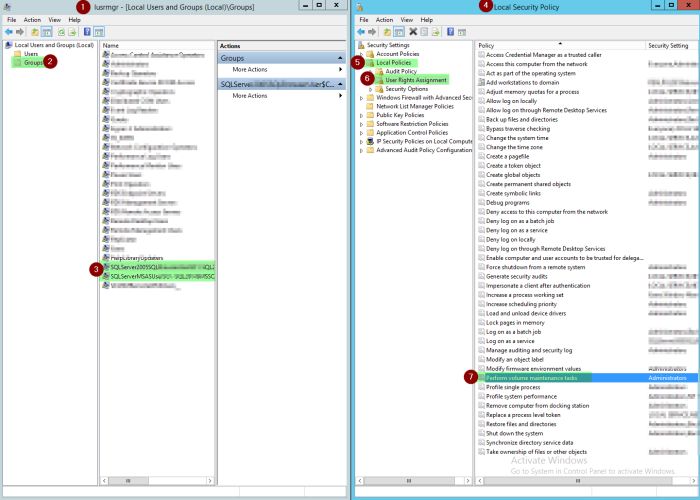
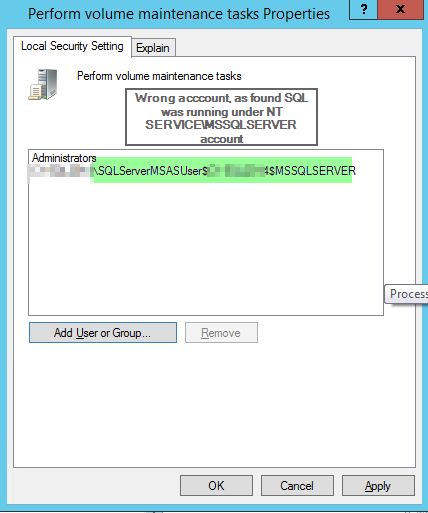
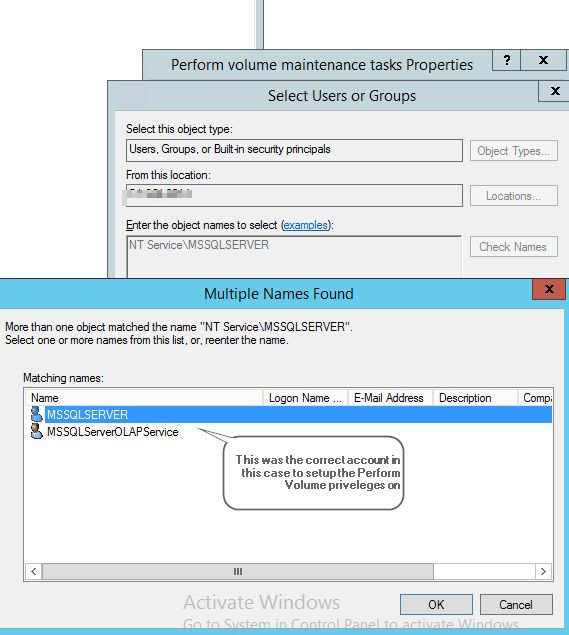
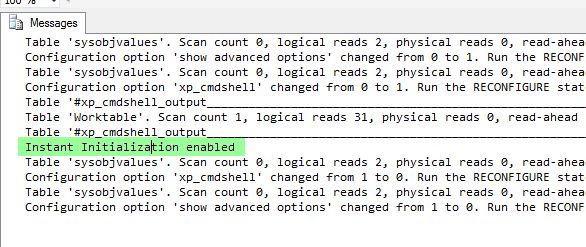

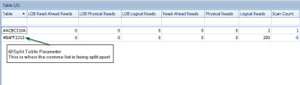

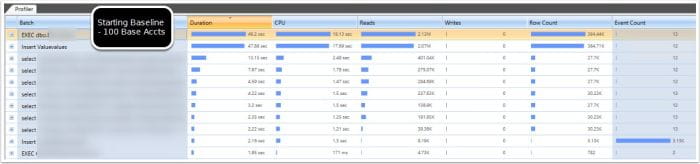
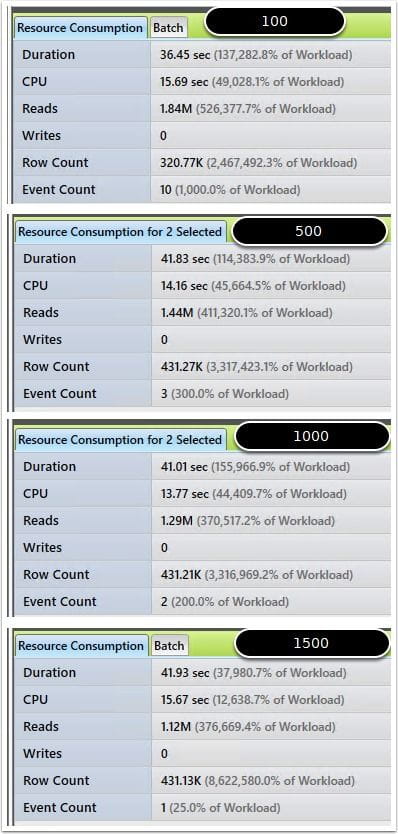
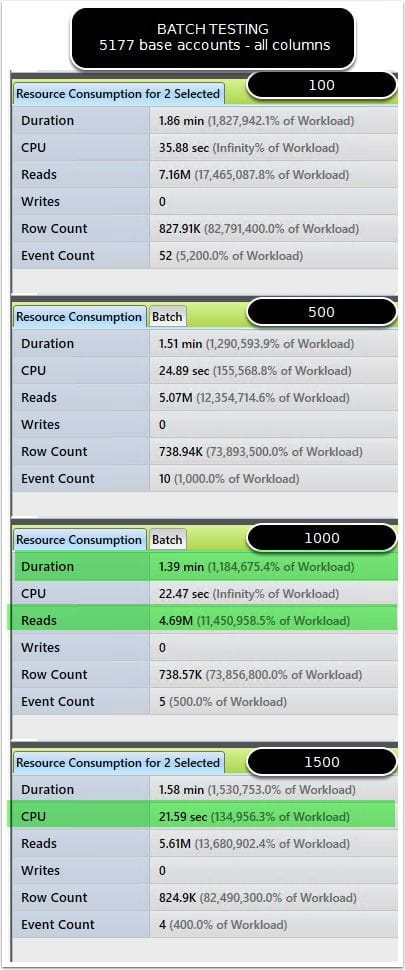
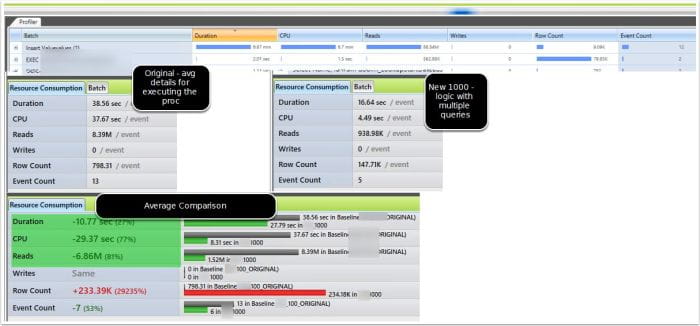
 The footprint is reduced when dealing with IO from the child statement, because it keeps pointing to the same in memory object. I also validated this further by examining a more complex version of the same query that compares the comma delimited list against executing a nested stored procedure, which in turn has dynamic sql that needs the table parameter passed to it. The results of the review show successfully that it keeps pointing to the same temp object!
The footprint is reduced when dealing with IO from the child statement, because it keeps pointing to the same in memory object. I also validated this further by examining a more complex version of the same query that compares the comma delimited list against executing a nested stored procedure, which in turn has dynamic sql that needs the table parameter passed to it. The results of the review show successfully that it keeps pointing to the same temp object!
