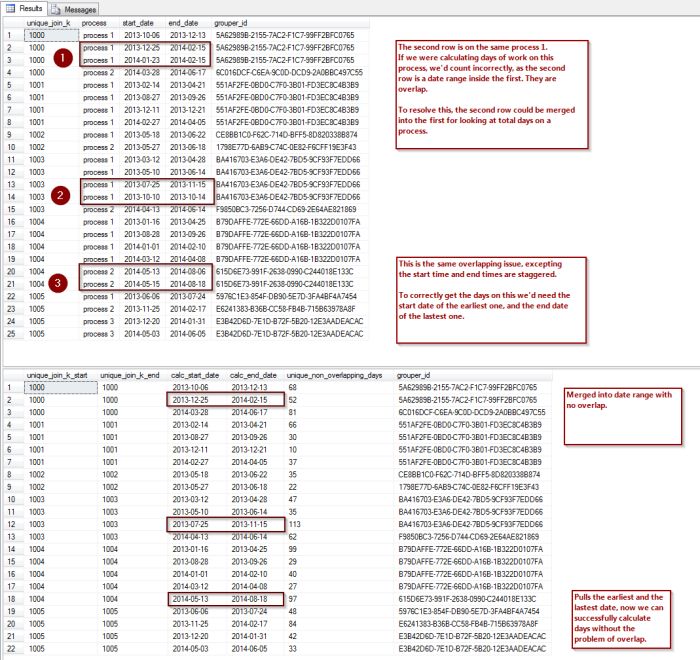
Eliminate Overlapping Dates
I was looking for an efficient way to eliminate overlapping days when provided with a historical table that provided events that could overlap. In my case, I had dates show the range of a process. However, the multiple start and end dates could overlap, and even run concurrently. To eliminate double counting the days the process truly was in play I needed a way to find eliminate the overlap, and eliminate duplicate days when running in parallel. I researched ways to complete this and found the solution through this post. Solutions to Packing Date and Time Intervals Puzzle
Itzik provided an excellent solution, though I had to take time to digest. The only problem I ran into, was his solution was focused on a single user and dates. For my purposes, I need to evaluate an account and further break it down by overlap on a particular process. Grateful for SQL MVP's contributions to the community as this was a brain bender!