- PowerShellers wanting to know how to create json and yaml dynamically via
pscustomobject.
- Anyone wanting to create configs like Datadog or other tools dynamically without the benefit of a configuration management tool.
- Anyone else wanting to fall asleep more quickly. (I can think of better material such as the Go spec docs, but hey, I can't argue with your good taste 😄)
It's readable.
It's probably cost all of us hours when debugging yaml that's nested several layers and an errant whitespace got in.
It's here to stay.
I prefer it over JSON for readability, but I prefer JSON for programmability.
Sometimes though, tooling uses yaml, and we need to be able to flip between both.
Historically I've used cfn-flip which is pretty great.
The problem I have with using cfn-flip is dependencies.
It's a bit crazy to setup a docker image and then need to install a bunch of python setup tools to just get this one tool when it's all I need.
I thought about building a quick Go app to do this and give me the benefit of a single binary, as there is a pretty useful yaml package already.
Instead, I found a robust package that is cross-platform called yq and it's my new go to. 🎉
The docs are great
Reading STDIN is a bit clunky, but not too bad, though I wish it would take more of a pipeline input approach natively.
Instead of passing in {"string":"value"} | yq it requires you to specify stringinput | yq eval - --prettyPrint .
Note the single hyphen after eval. This is what signifies that the input is STDIN.
I was working on some Datadog config generation for SQL Server, and found this tooling useful, especially on older Windows instances that didn't have the capability to run the nice module powershell-yaml.
Here's how to use PowerShell objects to help generate a yaml configuration file on demand.
See install directions for linux/mac, as it's pretty straightforward.
For windows, the chocolatey package was outdated as of the time of the article using the version 3.x.
I used a PowerShell 4.0 compatible syntax here that should work on any instances with access to the web.
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
if (-not (Test-Path 'C:\tools\yq.exe' -PathType Leaf))
{
$ProgressPreference = 'SilentlyContinue'
New-Item 'C:\tools' -ItemType Directory -Force
Invoke-WebRequest 'https://github.com/mikefarah/yq/releases/download/v4.4.1/yq_windows_amd64.exe' -OutFile 'C:\tools\yq.exe' -UseBasicParsing
Unblock-File 'C:\tools\yq.exe' -Confirm:$false
}
Once this was downloaded, you could either make sure C:\tools was in PATH or just use the fully qualified path for our simple use case.
In AWS, I parsed the metadata for the AccountID and InstanceID to generate a query to pull the Name tag dynamically.
{{< admonition type="Tip" title="Permissions Check" >}}
You must have the required permissions for the instance profile for this to work.
This is not an instance level permission, so you'll want to add the required DescribeTags and ListInstances permissions for using a command such as Get-EC2Tag
{{< /admonition >}}
Import-Module AWSPowershell -Verbose:$false *> $null
# AWSPowerShell is the legacy module, but is provided already on most AWS instances
$response = Invoke-RestMethod -Uri 'http://169.254.169.254/latest/dynamic/instance-identity/document' -TimeoutSec 5
$AccountId = $response.AccountId
Now we can pull back the tag using an EC2 instance filter object.
$filters = @(
[Amazon.EC2.Model.Filter]::new('resource-id', $response.InstanceId)
)
$tags = Get-EC2Tag -Filters $filters
$tagcollection = $tags.ForEach{
$t = $_
[pscustomobject]@{
Name = $t.name
Value = $t.value
}
}
Write-Host "Tags For Instance: $($tagcollection | Format-Table -AutoSize -Wrap | Out-String)"
$HostName = $Tags.GetEnumerator().Where{ $_.Key -eq 'Name' }.Value.ToLower().Trim()
$SqlInstance = $HostName
The next step was to alias the instance.
The better way to do this would be to use a tag that it reads, but for my quick ad-hoc use, this just let me specific an explicit alias to generate as a tag in the yaml. Again, try to use the Datadog tagging feature to do this automatically if possible.
{{< admonition type="Tip" title="Switch Statements" >}}
If you aren't familiar with PowerShell's switch statement, it's a nice little feature for making this evaluation easy to read.
For the breadth of what this cool language feature can do, check this article out:
Everything you ever wanted to know about the switch statement
{{< /admonition >}}
switch ($AccountId)
{
'12345' { $AWSAccountAlias = 'mydevenv' ; $stage = 'qa' }
'12345' { $AWSAccountAlias = 'myprodenv' ; $stage = 'prod' }
default
{
throw "Couldn't match a valid account number to give this an alias"
}
}
Now, preview the results of this Frankenstein.
Write-Host -ForegroundColor Green ("
`$HostName = $HostName
`$SqlInstance = $SqlInstance
`$AWSAccountAlias = $AWSAccountAlias
`$stage = $stage
")
$TargetConfig = (Join-Path $ENV:ProgramData 'Datadog/conf.d/windows_service.d/conf.yaml')
$Services = [pscustomobject]@{
'instances' = @(
[ordered]@{
'services' = @(
'SQLSERVERAGENT'
'MSSQLSERVER'
'SQLSERVERAGENT'
)
'disable_legacy_service_tag' = $true
'tags' = @(
"aws_account_alias:$AWSAccountAlias"
"sql_instance:$SqlInstance"
"stage:$stage"
)
}
)
}
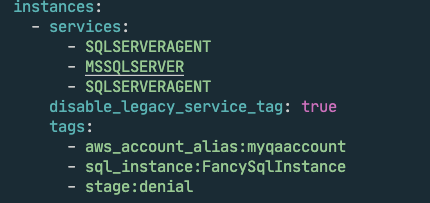
$Services | ConvertTo-Json -Depth 100 | &'C:\tools\yq.exe' eval - --prettyPrint | Out-File $TargetConfig -Encoding UTF8
This would produce a nice json output like this
Start with creating an empty array and some variables to work with.
$UserName = 'TacoBear'
$Password = 'YouReallyThinkI''dPostThis?Funny'
$TargetConfig = (Join-Path $ENV:ProgramData 'Datadog/conf.d/sqlserver.d/conf.yaml')
$Queries = @()
Next include the generic Datadog collector definition.
This is straight outta their Github repo with the benefit of some tagging.
$Queries += [ordered]@{
'host' ='tcp:localhost,1433'
'username' =$UserName
'password' = $Password
'connector' ='adodbapi'
'driver' = 'SQL Server'
'database' = 'master'
'tags' = @(
"aws_account_alias:$AWSAccountAlias"
"sql_instance:$SqlInstance"
"stage:$stage"
)
}
{{< admonition type="Tip" title="Using += for Collections" >}}
Using += is a bit of an anti-pattern for high performance PowerShell, but it works great for something like this that's ad-hoc and needs to be simple.
For high performance needs, try using something like $list = [Systems.Collections.Generic.List[pscustomobject]]:new() for example.
This can then allow you to use the $list.Add([pscustomobject]@{} to add items.
A bit more complex, but very powerful and performance, with the benefit of stronger data typing.
{{< /admonition >}}
This one is a good example of the custom query format that Datadog supports, but honestly I found pretty confusing in their docs until I bumbled my way through a few iterations.
$Queries += [ordered]@{
# description: Not Used by Datadog, but helpful to reading the yaml, be kind to those folks!
'description' = 'Get Count of Databases on Server'
'host' ='tcp:localhost,1433'
'username' = $UserName
'database' = 'master'
'password' = $Password
'connector' ='adodbapi'
'driver' = 'SQL Server'
'min_collection_interval' = [timespan]::FromHours(1).TotalSeconds
'command_timeout' = 120
'custom_queries' = @(
[ordered]@{
'query' = "select count(name) from sys.databases as d where d.Name not in ('master', 'msdb', 'model', 'tempdb')"
'columns' = @(
[ordered]@{
'name' = 'instance.database_count'
'type' = 'gauge'
'tags' = @(
"aws_account_alias:$AWSAccountAlias"
"sql_instance:$SqlInstance"
"stage:$stage"
)
}
)
}
)
}
Let me do a quick breakdown, in case you aren't as familiar with this type of syntax in PowerShell.
$Queries += takes whatever existing object we have and replaces it with the current object + the new object. This is why it's not performant for large scale work as it's basically creating a whole new copy of the collection with your new addition.- Next, I'm using
[ordered] instead of [pscustomobject] which in effect does the same thing, but ensures I'm not having all my properties randomly sorted each time. Makes things a little easier to review. This is a shorthand syntax for what would be a much longer tedious process using New-Object and Add-Member.
- Custom queries is a list, so I cast it with
@() format, which tells PowerShell to expect a list. This helps json/yaml conversion be correct even if you have just a single entry. You can be more explicit if you want, like [pscustomobject[]]@() but since PowerShell ignores you mostly on trying to be type specific, it's not worth it. Don't try to make PowerShell be Go or C#. 😁
Ok, we have an object list, now we need to flip this to yaml.
It's not as easy as $Queries | yq because of the difference in paradigm with .NET.
We are working with a structured object.
Just look at $Queries | Get-Member and you'll probably get: TypeName: System.Collections.Specialized.OrderedDictionary. The difference is that Go/Linux paradigm is focused on text, not objects. With powershell-yaml module you can run ConvertTo-Yaml $Queries and it will work as it will handle the object transformation.
However, we can actually get there with PowerShell, just need to think of a text focused paradigm instead. This is actually pretty easy using Converto-Json.
$SqlConfig = [ordered]@{'instances' = $Queries }
$SqlConfig | ConvertTo-Json -Depth 100 | &'C:\tools\yq.exe' eval - --prettyPrint | Out-File $TargetConfig -Encoding UTF8
This takes the object, converts to json uses the provided cmdlet from PowerShell that knows how to properly take the object and all the nested properties and magically split to JSON. Pass this into the yq executable, and behold, the magic is done.
You should have a nicely formatted yaml configuration file for Datadog.
If not, the dog will yip and complain with a bunch of red text in the log.
Use this on the remote instance to simplify some debugging, or even connect via SSM directly.
& "$env:ProgramFiles\Datadog\Datadog Agent\bin\agent.exe" stopservice
& "$env:ProgramFiles\Datadog\Datadog Agent\bin\agent.exe" start-service
#Stream Logs without gui if remote session using:
Get-Content 'C:\ProgramData\Datadog\logs\agent.log' -Tail 5 -Wait
# interactive debugging and viewing of console
# & "$env:ProgramFiles\Datadog\Datadog Agent\bin\agent.exe" launch-gui
Ideally, use Chef, Ansible, Saltstack, DSC, or another tool to do this. However, sometimes you just need some flexible options for generating this type of content dynamically. Hopefully, you'll find this useful in your PowerShell magician journey and save some time.
I've already found it useful in flipping json content for various tools back and forth. 🎉
A few scenarios that tooling like yq might prove useful could be:
- convert simple query results from json to yaml and store in git as config
- Flip an SSM Json doc to yaml
- Review a complex json doc by flipping to yaml for more readable syntax
- Confusing co-workers by flipping all their cloudformation from yaml to json or yaml from json. (If you take random advice like this and apply, you probably deserve the aftermath this would bring 🤣.)