A Smattering of Thoughts About Applying Site Reliability Engineering principles
What's This about
I figured I'd go ahead and take this article which I've gutted several times and share some thoughts, even if it's not an authority on the topic. 😀
In the last year, I've been interested in exploring the DevOps philosophy as it applies to operations as well as software development. I originally started various drafts on these concepts back before April 2019, but never got around to finishing it until now.
This isn't a very focused post, more a smattering of thoughts, so let's get to it! 💪
DevOps Is A Challenge
Having come from a development background, applying DevOps to the operational side of the fence is an interesting challenge.
There are so many things that can be unique to the evolving way a team you are part of is growing and learning, that it can be difficult sometimes to know what is "best practice" and was is "essential practice" in a DevOps culture.
- What does it mean to plan and scale your workflow in a DevOps culture?
- How do operational stability and the pressure for new feature delivery in a competitive market meet in a healthy tension?
- How do you do "everything-as-code" in practice?
- Lots more!
There are various ways to implement DevOps, and core principles to DevOps. I've found that one that really resonated with me as I've looked for how others have done this.
Site Reliability Engineering
Google's Site Reliability Engineering (SRE) material provides a solid guide on the implementation of SRE teams. They consider SRE and DevOps in a similar relationship to how Agile views Scrum. Scrum is an implementation of Agile tenants. Site Reliability Engineering is an implementation of a DevOps culture, with guidelines on how to approach this in a systematic way.
If you think of DevOps like an interface in a programming language, class SRE implements DevOps. Google SRE
What I like about the material, is that a lot of the fixes I've considered to improvements in workflow and planning have been thoughtfully answered in their guide, since it's a specific implementation rather than a broader philosophy with less specific steps.
Regardless of where you are in your journey, a lot of the principles have much to offer. Even smaller organizations can benefit from many of these concepts, with various adjustments being made to account for the capabilities of the business.
Recommended SRE Reading
Recommended reading if this interests you:
Where I Started
At the beginning of my tech career, I worked at a place that the word "spec" or "requirement" was considered unreasonable. Acceptance criteria would have been looked down upon, as something too formal and wasteful.
While moving towards to implementation of any new project, I was expected to gather the requirements, build the solution, ensure quality and testing, and deploy to production. That "cradle to grave" approach done correctly can promote the DevOps principles, such as ensuring rapid feedback from the end-users and ownership from creation through to production.
A Different Take
I've been in a somewhat interesting blend of roles that gives me some insight into this. As a developer, I always look at things from an 🤖 automation & coding perspective. It's the exception, rather than the norm for me to do it manually without any type of way to reproduce via code.
I've also been part of a team that did some automation for various tasks in a variety of ways, yet often resolved issues via manual interactions due to the time constraints and pressures of inflowing work. Building out integration tests, code unit tests, or any other automated testing was a nice idea in theory, but allocating time to slow down and refactor for automated testing on code, deployments, and other tasks were often deemed too costly or time prohibitive to pursue, in addition to requiring a totally different skillset to focus on.
For example, you can't write code based tests against a deployment, unless you have made the time and effort to learn to code in that language and work through the pain of discovery in writing integration oriented tests. It's not a simple feat 🦶 to just pick up a language and start writing tests in it if you've never done this before.
Reactive
Reactive work also challenges DevOps focused teams that do operational work.
- Difficult to categorize emergency from something that could be done in a few weeks
- Difficult to deliver on a set of fully completed tasks in a sprint (if you even do a sprint)
- High interrupt ratio for request-driven work instead of able to put into a sprint with planning. (This is common in a DevOps dedicated team topology that is in some of the Anti-Types mentioned in DevOps Anti-Type topologies)
- Sprint items in progress tend to stay there for more than a few days due to the constant interruptions or unplanned work items that get put on their plate.
- Unplanned work items are constant, going above the 25% buffer normally put into a sprint team.
- Continued feature delivery pressure without the ability to invest in resiliency of the system.
Google has a lot more detail on the principles of "on-call" rotation work compared to project-oriented work. Life of An On-Call Engineer. Of particular relevance is mention of capping the time that Site Reliability Engineers spend on purely operational work to 50% to ensure the other time is spent building solutions to impact the automation and service reliability in a proactive, rather than reactive manner.
In addition, the challenges of operational reactive work and getting in the zone on solving project work with code can limit the ability to address the toil of continual fixes. Google's SRE Handbook also addresses this in mentioning that you should definitely not mix operational work and project work on the same person at the same time. Instead whoever is on call for that reactive work should focus fully on that, and not try to do project work at the same time. Trying to do both results in frustration and fragmentation in their effort.
This is refreshing, as I known I've felt the pressure of needing to deliver a project, yet feeling that pressure of reactive work with operational issues taking precedence.
It's important to recognize the importance of that operational work. It helps ensure a team is delivering what is most important to a business, a happy customer base! At the same time, always living in the reactive world can easily cause the project related work and reliability improvements that will support those efforts to suffer if a intentional plan to handle this is not made.
Reducing Toil
I've always been focused on building resilient systems, sometimes to my own detriment velocity wise. Balancing the momentum of delivery features and improving reliability is always a tough issue to tackle. Automation isn't free. It requires effort and time to do correctly. This investment can help scaling up what a team can handle, but requires slower velocity initially to do it right.
How do you balance automating and coding solutions to manual fixes, when you often can't know the future changes in priority?
It can be applied to immediate needs
A leader I've worked with mentioned one great way is to ensure whatever solution you build is immediately applicable to solving work in progress. By this, he meant work that could immediately benefit a team, rather than building things for future possibilities that haven't yet come into play. This aligns with a LEAN mentality and there is a lot to like about it.
It solves an immediate pain
Another way I've begun looking at this is solving the key pain-points that are mentioned by others. I tend to look at many improvements, and it can be difficult to choose what area to tackle at times, as I can see value in many of them.
However, solving paint points that are directly impacting someone enough that they are asking for help should take precedence in many cases (not all).
Why? This pain-point solved gains you an immediate win.
If you are solving an issue that others are ok with, or don't recognize as an issue, then you have an uphill battle for adoption compared to solving something immediately impacting their work. This doesn't negate addressing problems that others have not yet recognized, it is just something that's become clear can help in moving forward with improvements with less resistance.
Last Priority - Solving Problems No One Yet Knows They Need Solved
There is an important caveat to all of this. There is a realm of problems when you have expertise in an area that you will identify that others don't see. When assessed against goals of a business, these can be critical.
In my experience, the only way for these identified issues to be clearly prioritized is having a strong ability to communicate the problem and design some clear objectives to place this into the team backlog to address.
Verbally communicating, while important, won't have any staying power compared to a clearly defined objective in a backlog and advocated for in a presentation that helps raise concern for the same issue you care about.
They key is that your signal-to-noise-ratio is good, and when you raise the concern about the issue others don't have to work hard to understand why it's a problem.
How to balance product vs reliability improvements
SREs balance the juggling of product velocity and reliability improvements in a unique way... the usage of SLO and the error budget concept.
SLO & Error Budgets
The concepts of having an error budget really struct home for me. Clear Service Level Objectives (SLO) and error budgets to work with helps ensure both the development velocity and stability desired by operations is handled correctly.
Error budgets provide the key ingredient to balancing new feature delivery, while still ensuring happy customers with a stable system.
One of the best sections I've read on this was: Embracing Risk.
Error budgets are discussed, and internal SLI (Server Level Indicators). These are integral to ensuring a balance of engineering effort in balance with new feature delivery. The goal of 100% reliability, while sounding great, is inherently unrealistic.
Product development performance is largely evaluated on product velocity, which creates an incentive to push new code as quickly as possible. Meanwhile, SRE performance is (unsurprisingly) evaluated based upon the reliability of a service, which implies an incentive to push back against a high rate of change. Information asymmetry between the two teams further amplifies this inherent tension.
Wrap Up
I've been mulling over this for a while, and find a lot of the concepts very helpful as I've been challenged with both operational and development focus. As always, these are personal thoughts and don't reflect the opinion of my employer. I hope it gives you some food for thought. If you have some feedback, just post up a comment and let's dialogue!
 )
)
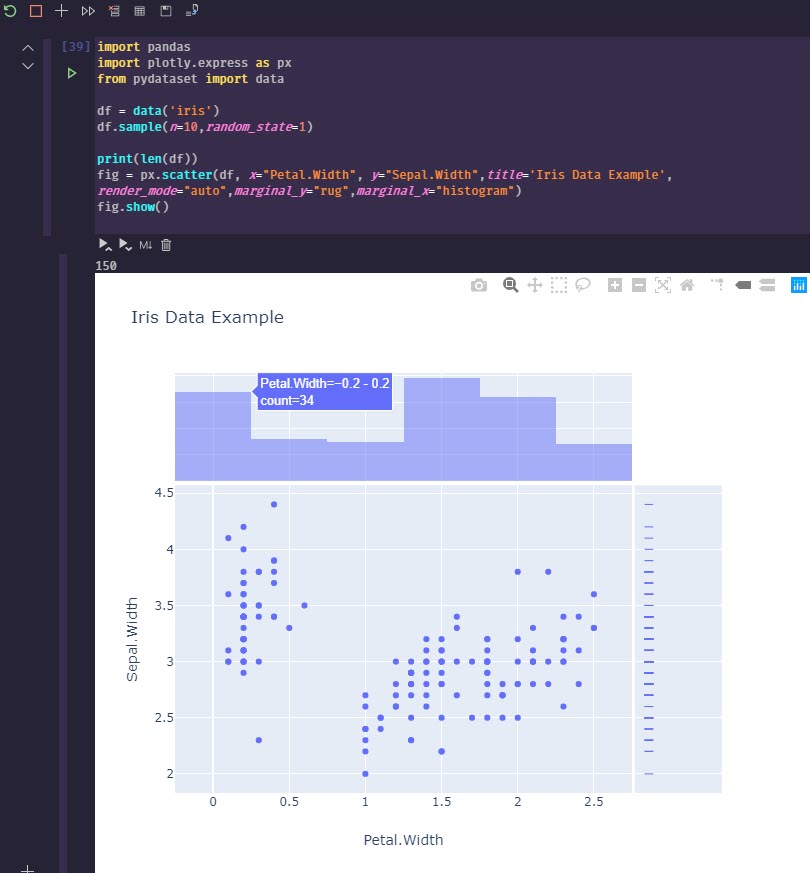
 . I'll definitely be spending more time learning how to manipulate and query datasets with Python, and eventually give Dash by Plotly a try as well. I've enjoyed Grafana, but it's really meant for time series monitoring, not for the flexible data visualization options that can be done so easily in Python.
. I'll definitely be spending more time learning how to manipulate and query datasets with Python, and eventually give Dash by Plotly a try as well. I've enjoyed Grafana, but it's really meant for time series monitoring, not for the flexible data visualization options that can be done so easily in Python.



 There are a couple ascii layouts that are a little inappropriate, so if doing a live demo or something more visible don't use random mode if you don't want something showing up that might embarass you
There are a couple ascii layouts that are a little inappropriate, so if doing a live demo or something more visible don't use random mode if you don't want something showing up that might embarass you