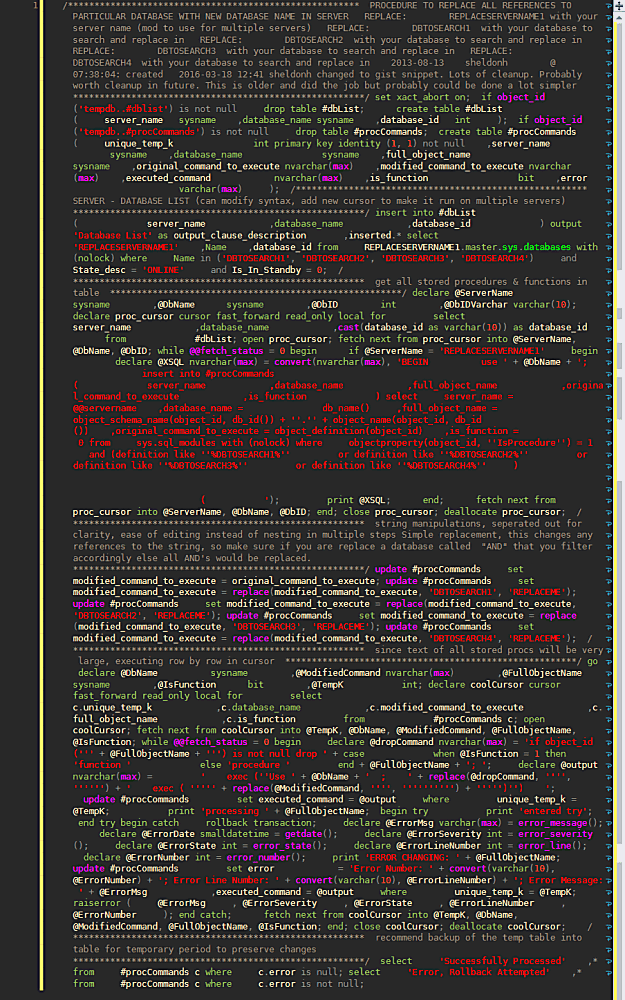
Redgate SQL Data Compare & Devart DBForge Data Compare
I'm a big fan of Redgate, as I'm in the Friend of Redgate program. However, I do also utilize some other toolkits. One competitor that I find has some , but I do dabble with some other toolkits (I know heresy :-) . One of the competitors that I find has some brilliant features, but many time lacks the refinement and ease of use of Redgate is Devart tools. The tools they offer are often really nice, and continually updated based on feedback. As a general rule, I'd say the Devart tools feel less "refined" in some areas, but then offer some really nice usability features that RG hasn't yet implemented. Both have their place in my toolbelt depending on the need.Having just completed some very large data comparisons on views, generating over 15GB of network traffic in last few days, I've been really impressed with the usability and output from Devart DbForge Data Compare. The performance seems great.
I've evaluated their schema compare before and found it fantastic for the price if I was strapped on a budget, but when able to pay for an overall more flexible and refined product I'd definitely choose SQL Compare. The differences are much smaller on the data compare tool though due to the much less complex nature of what it's performing. I ran across a few features in that I thought would be great to mention for the team working on Data Compare to provide some enhanced functionality.
Diff Report: They provide a fantastic option of outputting a diff report not only in CSV but in XLS format. The formatted report is much more usable than the CSV I get from RG Data compare because they format, and apply bold to the _S and _T cells that actually have a difference, enabling a much easier review process to find the diffs. This is far more usable for an end audience that might want to view differences in data detected on a table. I've had the case to provide this report to analysts to look at differences. The typical use case of DBA's syncing data from one database to another probably would just use the tool and never need this. My particular use case has found a better report output would have been a major benefit.
Cached schema object definitions/mapping. They load up previous mappings so you can go and tweak without the need to refresh immediately. This would be nice when you are fine tuning the comparison results and keep needing to tweak to the figures.
Other suggestions based on my recent work w/large table comparison.
Since table size has a direct impact on the compare due to local caching of the data, consider providing a column that shows estimated & total space required for the comparison. This way if I compared a lot of small tables I'd see the rowcount/size (sp_spaceused) and then added a large table (3GB for example), I'd see the approx local storage and network transfer impact with total size of "7GB total storage/transfer required".
If I setup a comparison on a view with custom key (due to no index on the view), and I drop and recreate the view for a new definition, the comparison options are not persisted (for example the custom key). I'm not sure if this is due to the underlying changes on the object_id and lack of clustered index for explicit mapping, but persisting this would be really nice when the columns used for key comparison still exist.
Overall, as a friend of Redgate I'm